




在数据库中,SQL是用户首先感知的部分,用户只需进行『声明式』地编程,不需要指明具体的执行过程,即可从复杂的存储结构中获得想要的数据。在此过程中,优化器发挥的作用功不可没,向前承接用户查询,向后为执行指明方向,可谓是数据库的大脑。
对优化器的研究从上世纪七十年代既已开始,到如今已经发展了数十年,其中有很多里程碑式的进展,例如Volcano/Cascades。在近些年新出现的一些数据库中,例如TiDB、CockroachDB、GreenPlum、Calcite等,也已经开始探索和尝试Cascades技术。
本文将围绕Cascades Optimizer,对其问题背景、理论原理、设计空间进行分析,同时也会对具体的工程实现做一些介绍。
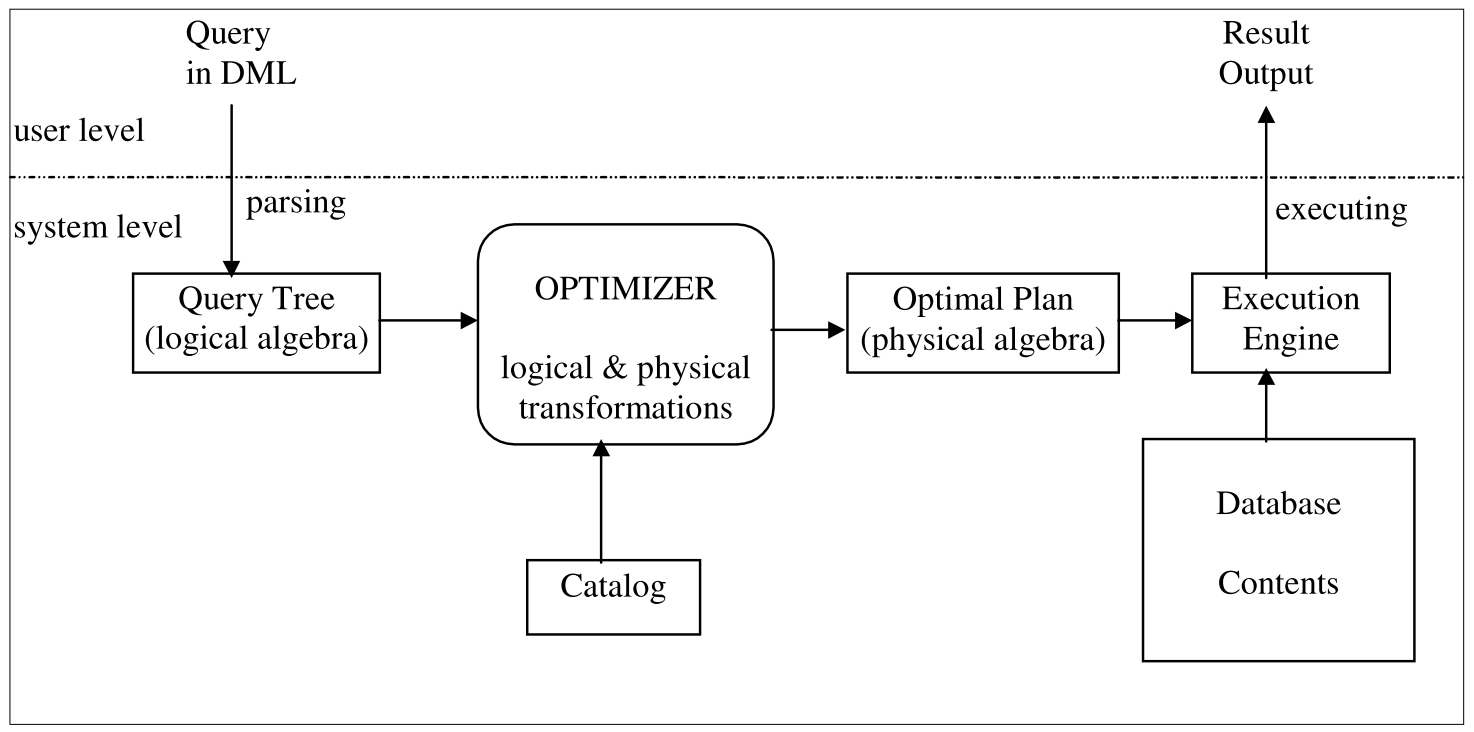
首先需要讨论的一个问题是,什么是优化器?
很多时候我们在讨论优化器的时候,其实讨论的是优化规则。一些常见的优化规则,例如谓词下推、常量折叠、子查询内联,这些想必不用赘述。对于具体规则来说,有些规则一定能带来收益,减小查询的代价,但另一些却未必,甚至会增加查询的代价。
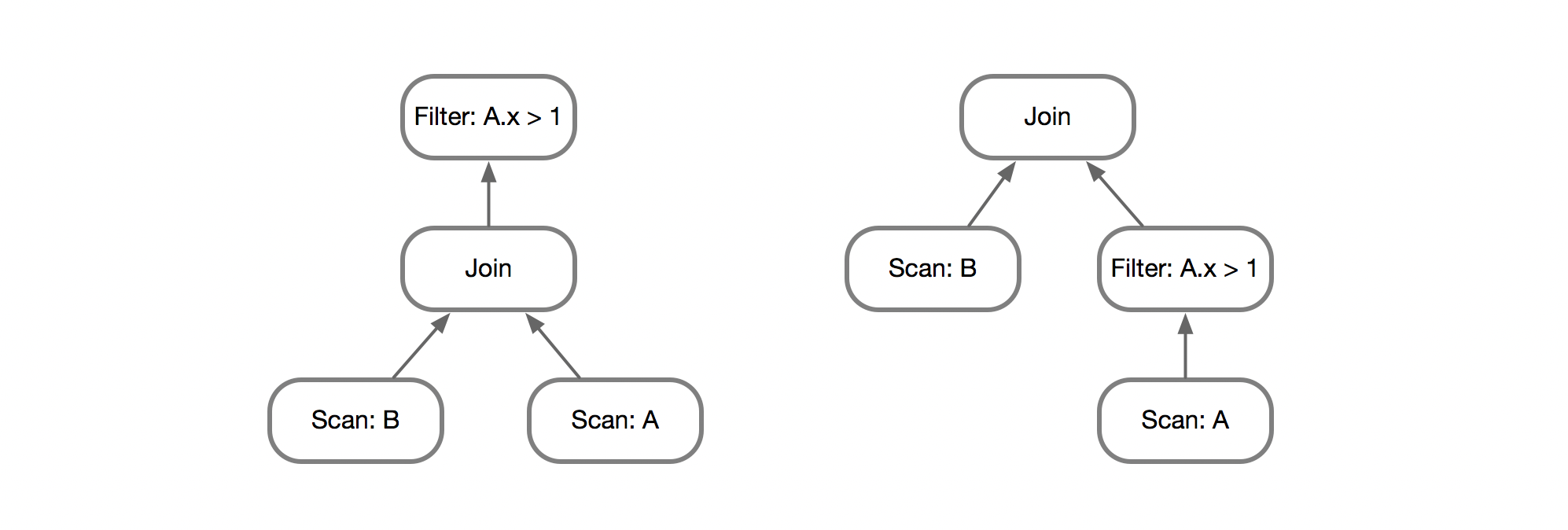
例如这里将谓词下推到具体的Scan算子上,由于能够减少Join时需要处理的数据量,显然是能够带来收益的。
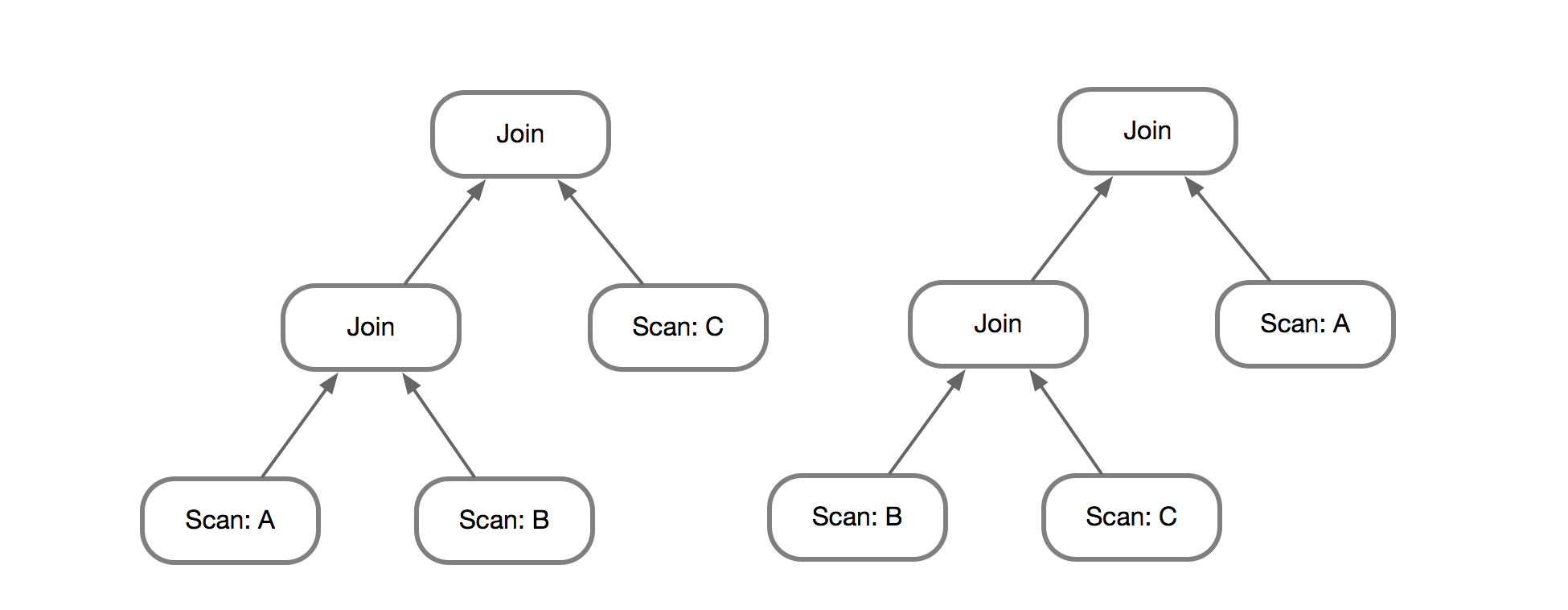
但对于Join顺序的枚举来说则未必,这里将原本的(A JOIN B) JOIN C替换成(B JOIN C) JOIN A,也许能带来收益。例如A有1000条数据,B有100条,C有10条数据,三个表之间存在一定的Join谓词使得,A JOIN B返回10000条数据,B JOIN C返回200条数据;如果采用最朴素的NestLoop,那么前一个执行计划需要处理1000 * 100 + 10000 * 10=200000次循环,而后一个执行计划则需要处理100 * 10 + 200 * 1000=200100次循环,因此前者会更优一点。
那么此时就会面临选择,需要从多个执行计划中选择出最优的。一种也许可行的方式就是『经验主义』,也称之为Heuristic-Based,例如『按照表从小到大的顺序Join』就是一条Heuristic,但比较遗憾的是,这条规则并不适用于所有场景,在上面的(B JOIN C) JOIN A的执行计划并不如从大到小来的好。另一种方式则是『数据主义』,也称之为Cost-Based,这种方式就需要事先进行统计,对数据量、数据分布等情况进行估算,遇到选择时就可以利用这些统计信息来评估不同的执行计划的好坏。
事实上这两种方法并不是泾渭分明的,如今的数据库基本已经没有完全基于经验的优化器实现了,多少都会基于代价来对计划进行评估,并且也会包含人为设定的经验。也就是说,优化器可以分解成三部分:
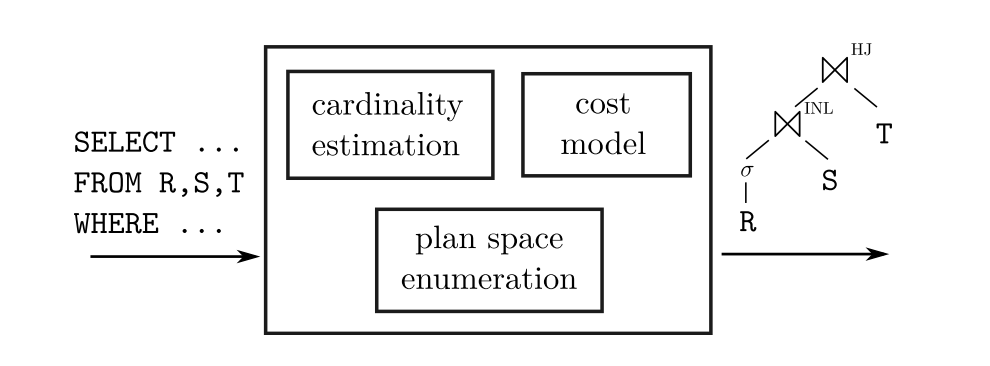
优化器的统计信息、代价模型、计划搜索几个问题都值得深究,这里仅仅涉猎计划搜索这一问题。
对于一个成熟的优化器来说,可能有几百条规则,每条规则都会作用于查询树,并产生一个逻辑等价的执行计划,因此我们可以把优化的问题理解为搜索的问题。更进一步,可以应用动态规划的思想,即可以把原问题分解成子问题来解决复杂问题。动态规划有几点需要注意(引用自Wikipedia):
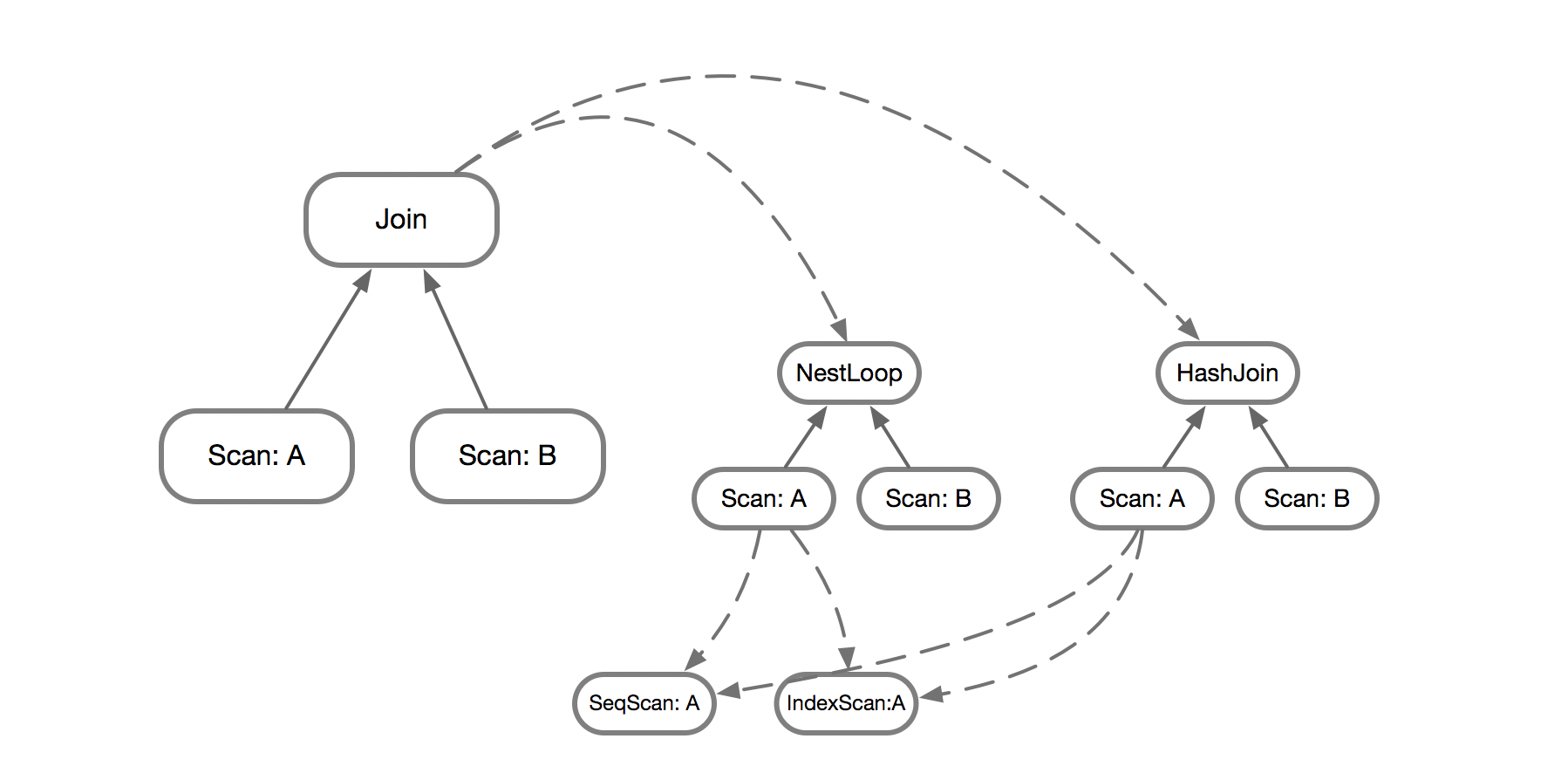
具体到查询这一问题,对于初始的Join Tree来说,Join算子会有多种实现,例如NestLoop和HashJoin,也即Join可以分解为两个子问题,NestLoop和HashJoin。而对于NestLoop来说,需要求解其子节点SCAN A和SCAN B,SCAN也有多种实现,例如SeqScan和IndexScan。同时,这里遇到了重叠子问题,在求解HashJoin的时候也需要计算SCAN A。
通过将原问题分解成对子问题的求解,再佐之以代价模型,即可在茫茫的搜索空间中,选中那万中无一的查询计划了。
具体在搜索时有两种流派,一种是以System R为代表的自底向上,另一种则是Cascades流派的自顶向下。
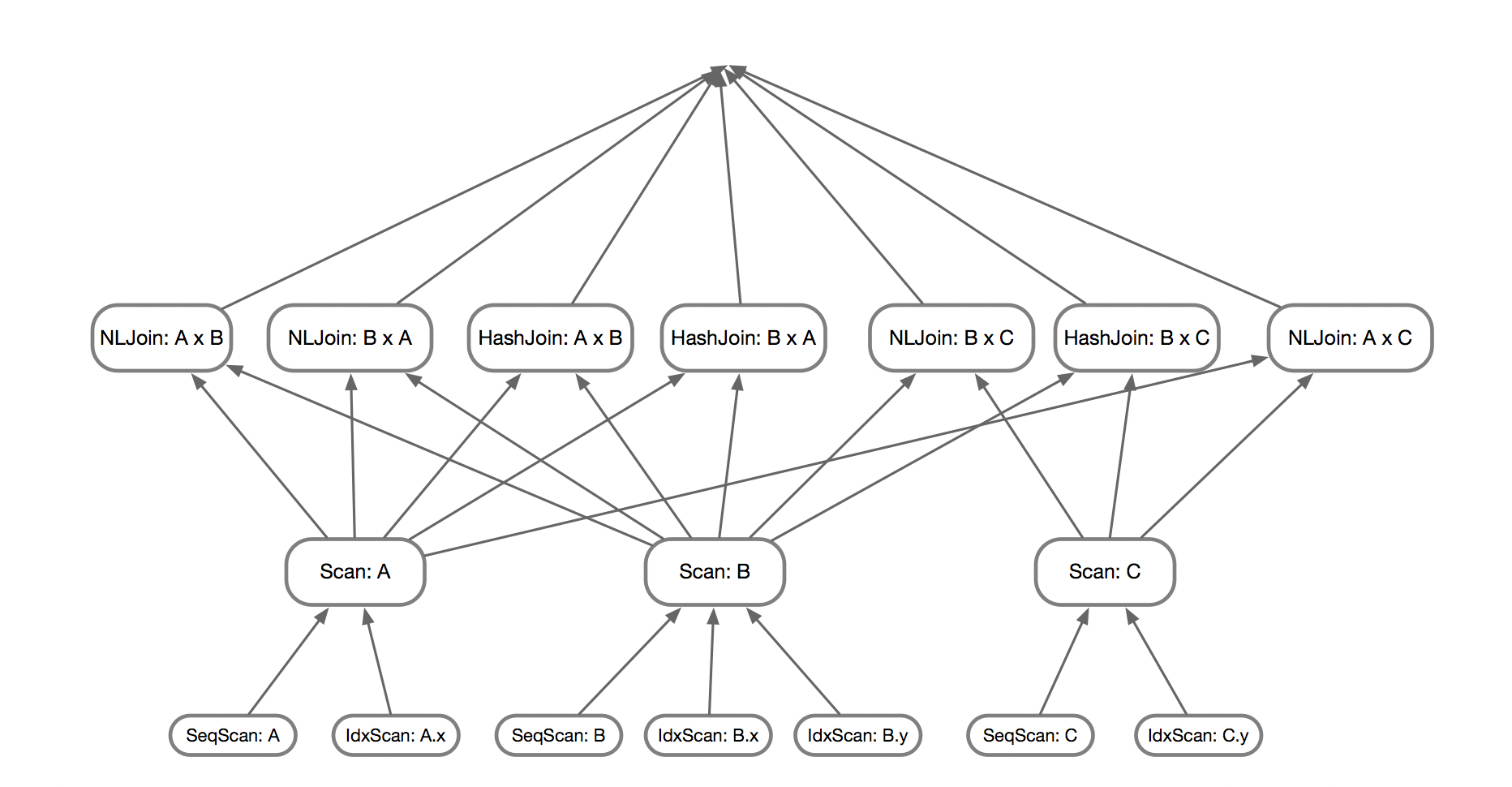
自底向上的算法会先计算基表的访问路径(Access Path),通常来说存在几种:顺序扫描、索引扫描、组合索引等,而存在多个索引时,每个索引都视作一个访问路径。接着,枚举两表Join,这里同时还需要对Join的物理实现进行枚举,所以第二层的状态会比第一层多许多。一层层往上搜索,即可得到多表Join的执行计划。
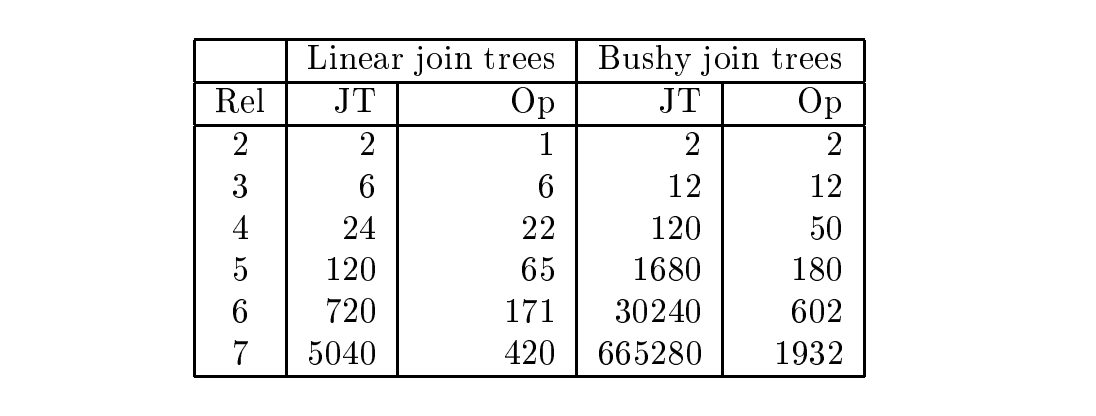
在搜索过程中,如果是纯粹地枚举所有可能的组合,则搜索空间会非常大。因此通常会对Join Tree的形状进行限制,也会在搜索过程中进行一定的剪枝。
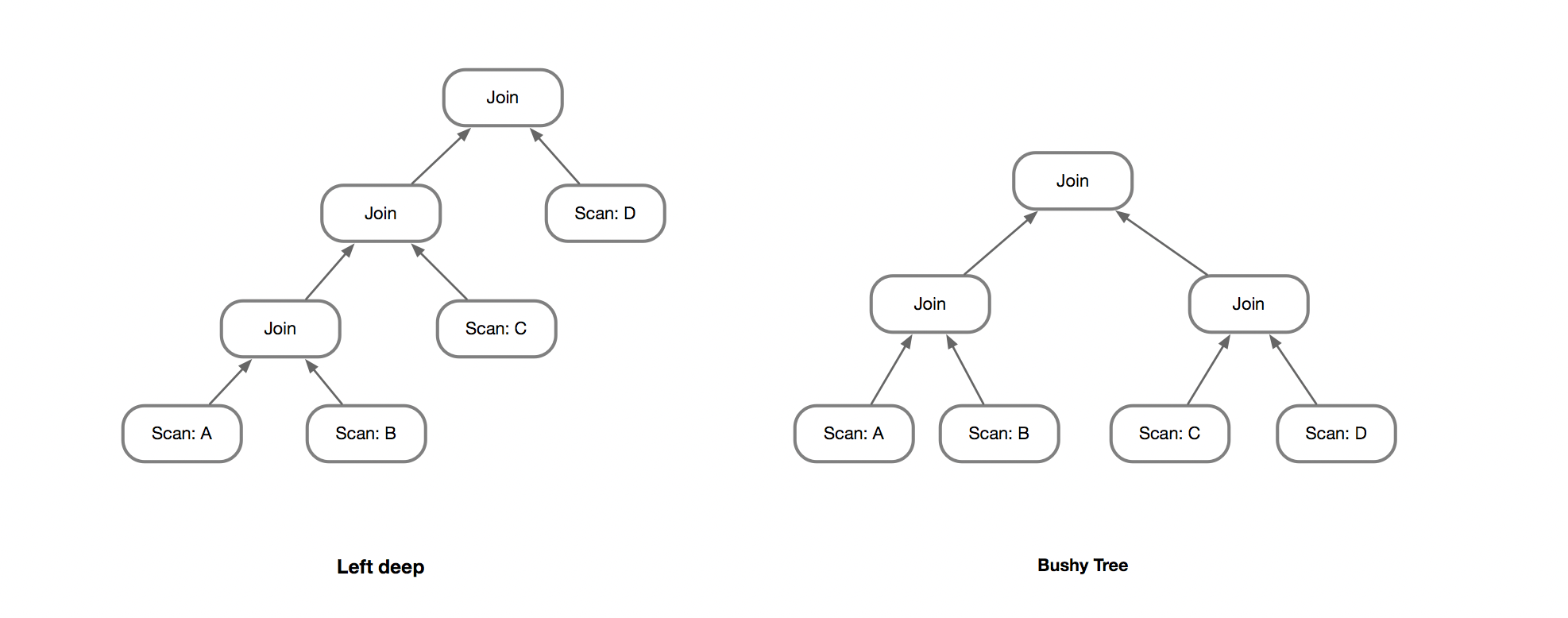
例如这里的两种典型的Join Tree,Left-deep和Bushy-Join。相比于Bushy-Tree的(2n-2)!/(n-1)!的复杂度,Left-Deep只有n!,搜索空间小了很多。
在搜索过程中,每一层不需要保留所有的组合,而是保留代价最低的即可。但需要考虑到一个问题,两表Join的最优解,未必能得到三表Join的最优解,例如两表用了HashJoin,那么输出的结果会是无序的;相比之下,如果用MergeJoin,两表Join可能不是代价最小的, 但是在三表Join时,就可以利用其有序性,对上层的Join进行优化。
为了刻画这个问题,引入了Interesting Order,即上层对下层的输出结果的顺序感兴趣。因此自底向上枚举时,A JOIN B不仅仅是保留代价最小的,还需要对每种Interesting Order的最小代价的Join进行保留。例如A JOIN B输出的顺序可能是(A.x), (A.x, B.y), (None)等多种可能性,就需要保留每种Interesting Order。
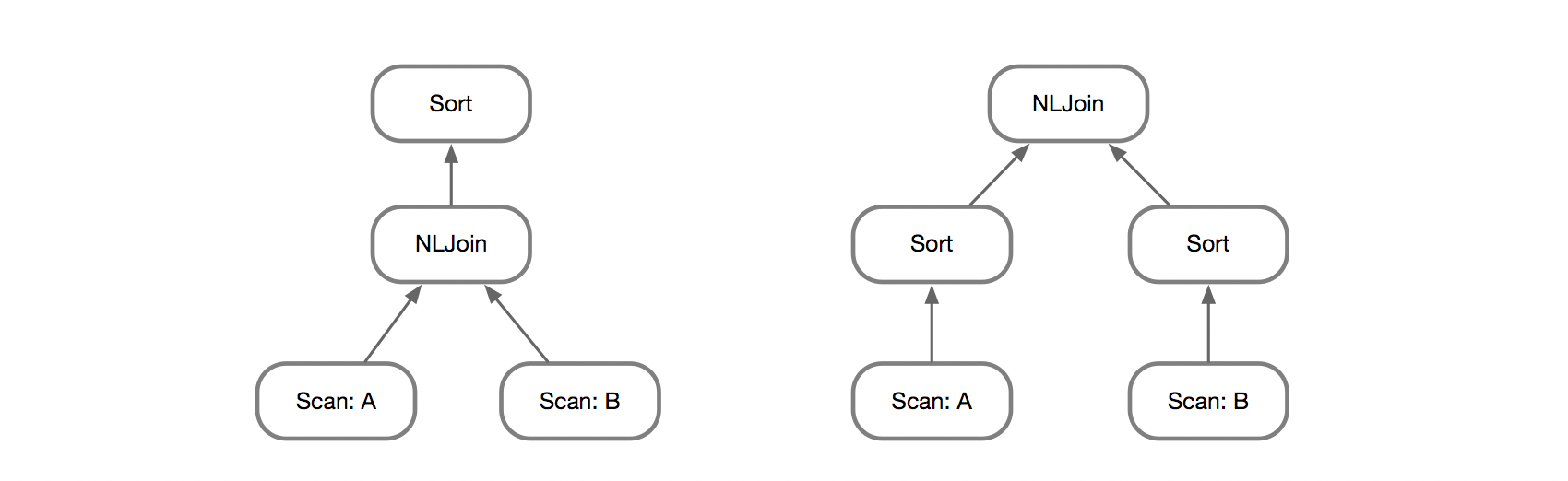
这里其实引出一个问题,自底向上的搜索过程中,下层无法知道上层需要的顺序,即便保留所有的Order,也未必能得到最优解。例如对A、B两表做笛卡尔积再排序,其代价可能要比先排序在做Join要高,但是在枚举Join时,无法知道上层需要的顺序,也就无法搜索这个计划。
join_search() {
join_levels[1] = initial_rels;
for (level : 2 -> N) {
join_search_one_level() {
// linear
for (outer : join_levels[level-1]) {
for (inner : join_levels[1]) {
if (overlap(outer, inner)) {
continue;
}
if (!has_restriction(outer, inner)) {
continue;
}
join_levels[level].add_path(make_join_rel(outer, inner));
}
}
// bushy
for (k : 2 -> N - 2) {
for (outer : join_levels[k]) {
for (inner : join_levels[N-k]) {
...
}
}
}
// cross-product
}
}
}PostgreSQL实现的Join算法就是经典的自底向上的动态规划,上面是其伪代码:
[2, N-2]层的Relation和N-k层的Relation进行组合注意到其中一个细节,尝试组合两个Relation时,会判断两个Relation是否存在Join 谓词,例如JOIN A, B ON A.x=B.x,如果有连接谓词作为过滤条件,生成的结果会大大减少。这种先枚举再测试连通性的方式称之为『generate and test』,在特定的场景下效率并不高,test这个步骤占据了很大开销,存在一定的优化空间,后面会做介绍。
经过以上的铺垫,自底向上的方法基本有了一个轮廓,同时我们在探索的过程中也意识到自底向上的一些局限性:
为此,我们尝试另一种思路,自顶向下的搜索方案:Cascades。Cascades其实是继承了Volcano Optimizer Generator,并做了很多优化,也对算法细节做了更多工作,因此我们直接跳过Volcano来看Cascades。
自顶向下个人感觉更加直观一点,对于一个Operator Tree来说,从根节点往下遍历,每个节点可以做多种变换:
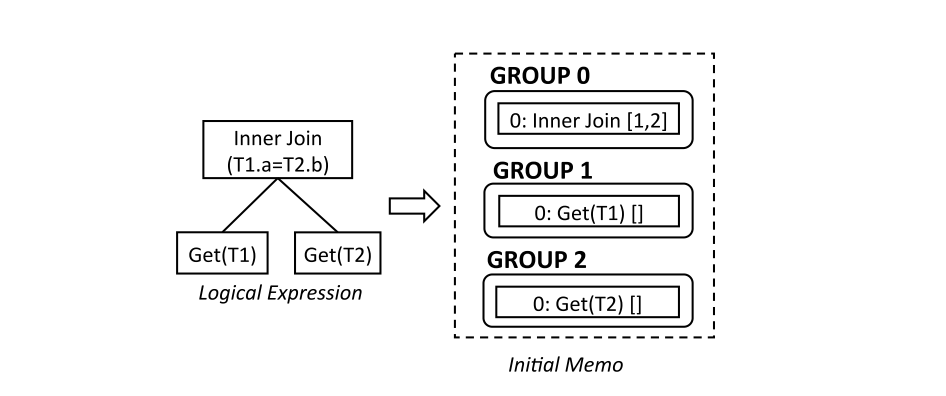
自顶向下的搜索过程中,整个搜索空间会形成一个Operator Tree的森林,因此很重要的一个问题是,如何高效地保存搜索状态。
Cascades首先将整个Operator Tree按节点拷贝到一个Memo的数据结构中,每个Operator放在一个Group。对于有子节点的Operator来说,将原本对Operator的直接引用,变成对Group的引用。例如上图的Group 0,引用了Group 1 和Group 2。
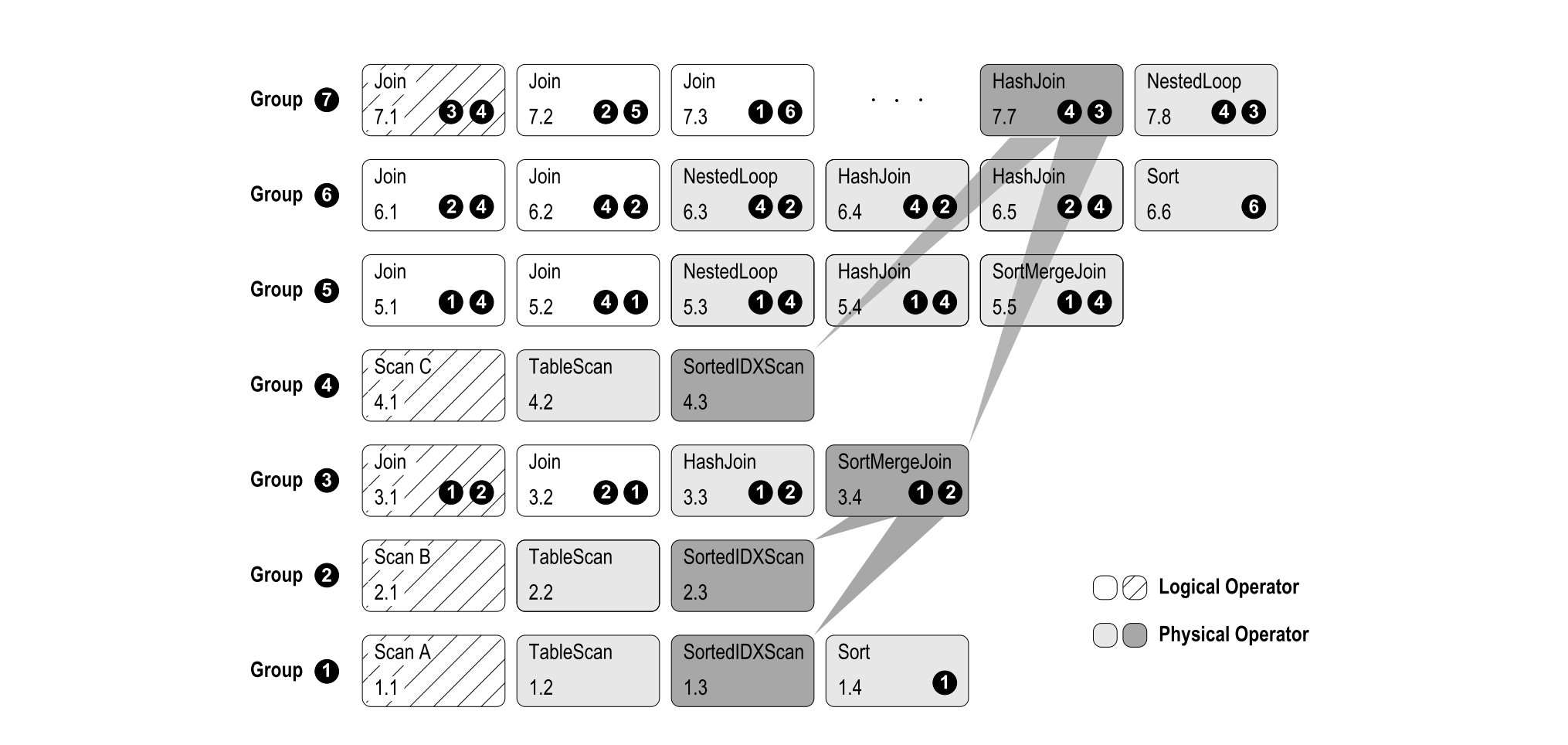
而每个Group中会存在多个成员,成员通常称之为Group Expression。成员之间是逻辑等价的,也就意味着他们输出的结果是一样的。随着搜索过程的推进,对Operator Tree进行变换时会产生新的Operator Tree,这些Tree仍然存储在Memo中。例如上图的的Group1,既包含了初始的Scan A,也包含了后续搜索产生的TableScan、SortedIDXScan。由于Group引用的是其他Group,这里可以视作形成了一个Group Tree,例如上面的Group 7 引用了 Group3、Group4,Group3又是一个Join算子,引用了Group1、Group2。
在搜索完成之后,我们可以从每个Group中选择出最优的Operator,并递归构建其子节点,即可得到最优的Operator Tree。
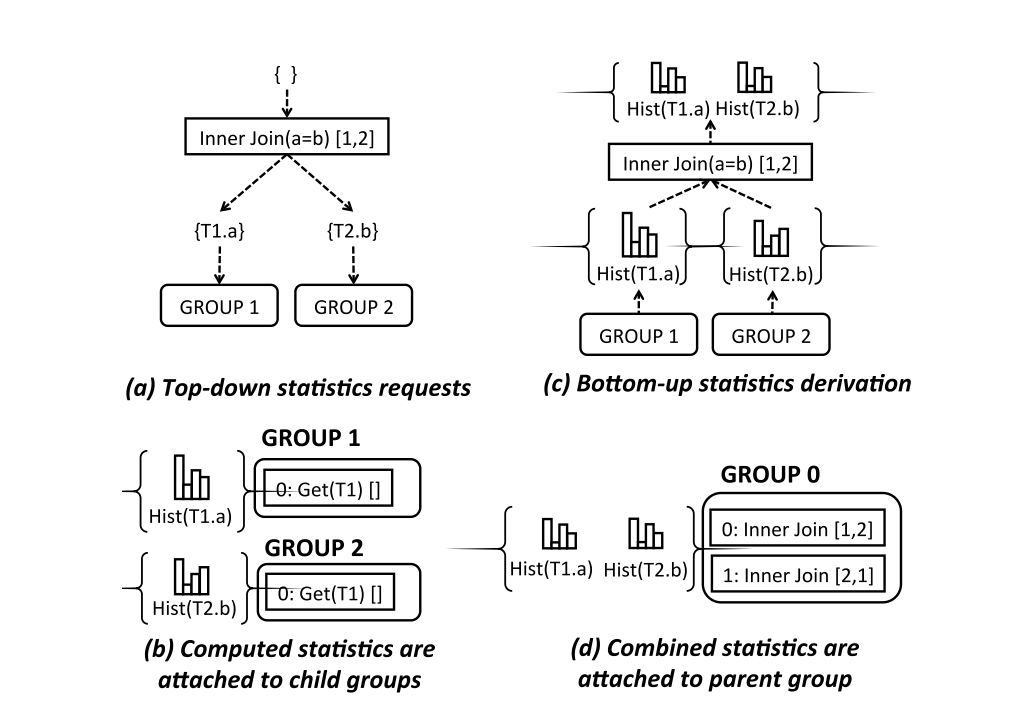
在搜索过程中,需要对Group Expression的代价进行评估,而代价评估则依赖于统计信息。统计信息的构建是一个自底向上的过程,每个基表维护直方图等统计信息,向上可进一步推导出Join 的统计信息。由于Group中的多个Expression是逻辑等价的,因此他们共享一个statistics。这一过程称之为『Stats Derivation』。
前面提到自顶向下的搜索可以进行更多的剪枝,这里的原理是根据代价的upper bound剪枝。将最初的Operator Tree的代价计算其lower bound和upper bound,之后的搜索过程中,如果还没搜索到最底层的节点,其代价已经超过了upper bound,那么这个解决方案即可放弃,不会更优只会雪上加霜。
理想情况下,这种剪枝能过滤掉很多不必要的搜索,但依赖于初始计划的代价。初始计划如果很糟糕,代价很大,对后续的搜索将无法发挥剪枝的作用。因此通常的优化器会在搜索之前进行称之为Transformation/Rewrite/Normalize的阶段,应用一些Heuristic的规则,预先对Plan进行优化,减小后面的搜索空间。
优化规则和搜索过程是Cascades的核心,也是优化器的工作重心。在传统的优化器实现中,往往是面向过程的,一条一条地应用优化规则,对Operator Tree进行变换。这种hardcode的方式往往难以扩展,想增加一条规则较为困难,需要考虑规则之间的应用顺序。而Cascades在处理这一问题时,将搜索过程与具体的规则解耦,用面向对象的方式对优化规则进行建模,规则的编写不需要关心搜索过程。
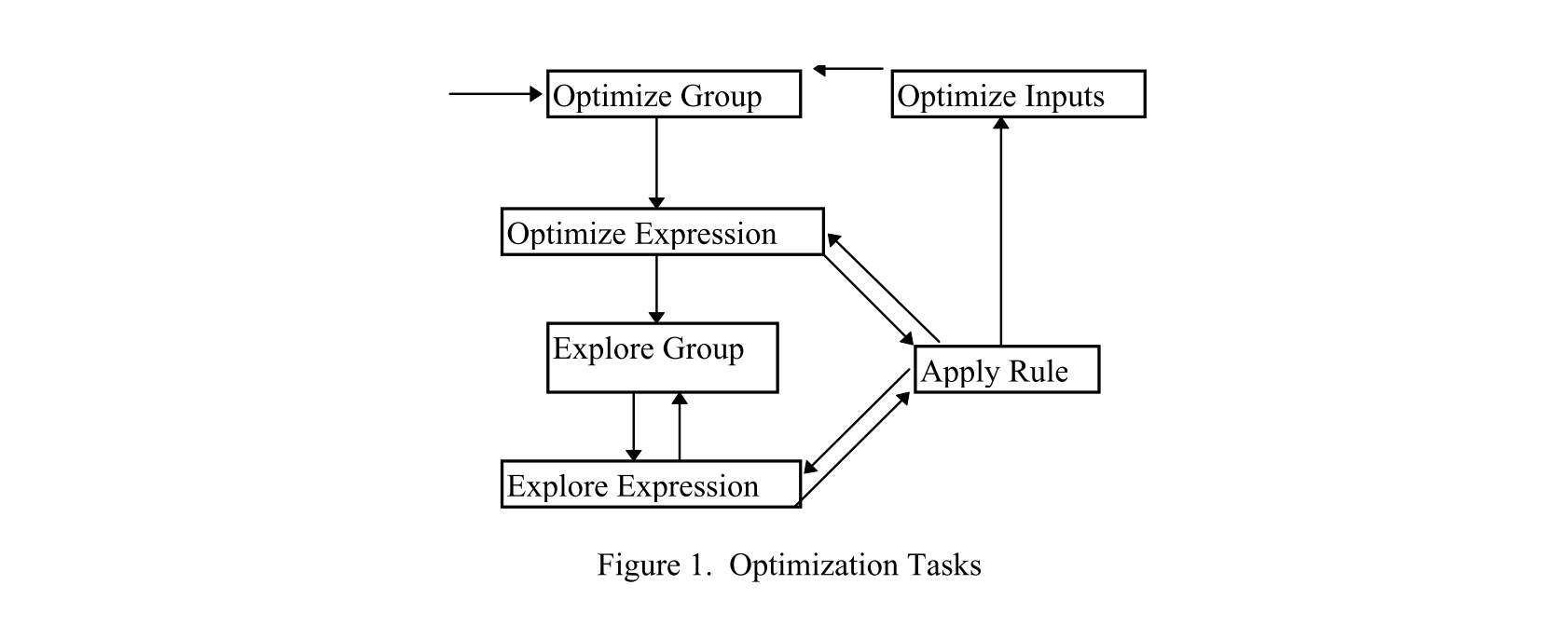
这里的搜索过程分解为几种Task:
这些Task会进行递归搜索,因此有两种选择,一种是直接递归调用,另一种则是用一个显式的的Stack,对任务进行调度:

前面提到Interesting Order的问题,在自顶向下的搜索过程中可以更加优雅地解决。这里讲Interesting Order的问题推广到Property,在分布式数据库的场景下,Property包含了数据分布的方式。例如分布式HashJoin要求两个表按照Hash分布,如果不满足这个属性,则需要对数据进行一次重分布。
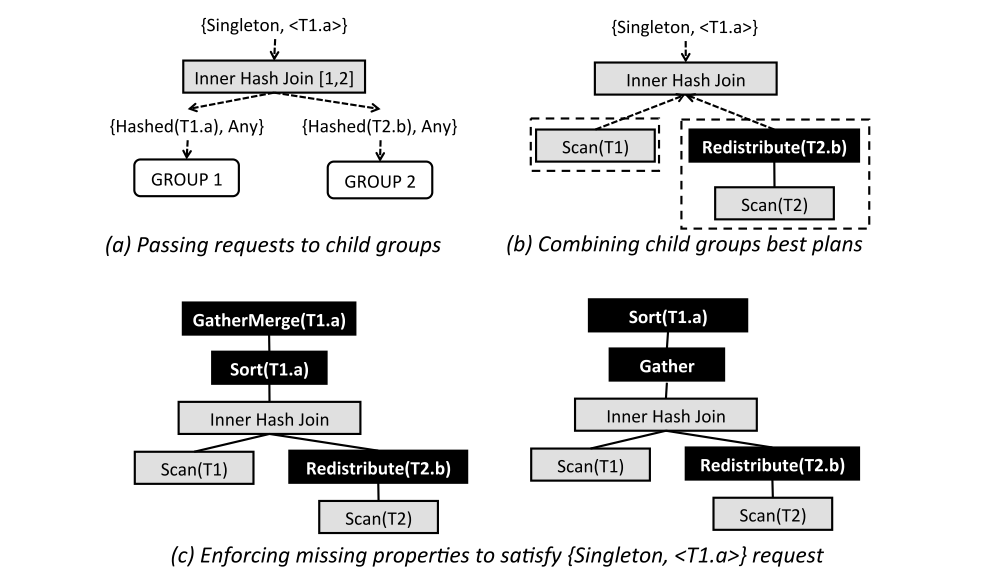
自顶向下的搜索过程可以用需求驱动的方式来计算属性,例如需要对T1.a进行排序的方式有多种,即可分解成多个子问题,对HashJoin的结果进行归并排序,或者把数据收集到一个节点之后再进行排序,都是可能的解决方案。对于不同的解决方案仍然是基于代价来选择出最优的方案,从而形成整体的最优解。
至此,基本覆盖了Cascades的原理,虽然理解起来很简单,但具体实现需要考虑更多的问题,工程实现的细节在这里无法一一枚举,有兴趣可参考具体的实现。在工业界,Peleton、Orca、SQL Server、Calcite、Cockroach等都算是Cascades的实现,其中不乏开源的优秀实现。
对自顶向下和自底向上的方法有了基本的理解之后,再来看下优化相关的其他问题。
优化器通常都包含了大量的规则,诸如谓词下推、Join交换算是最为简单的规则,除此之外还有很多复杂的规则。实现这些规则最为直接的方式就是用通用的编程语言编写,但其劣势在于缺乏可读性,且代码繁琐而庞大,长远来看影响可维护性。
在CockroachDB中,采用了DSL来实现规则。覆盖了从表达式优化,到搜索的所有规则。相比之下,可读性更高,且代码量小了很多,大部分规则用寥寥几行代码即可实现。=>上半部分是匹配规则,下半部分是替换规则。
# NormalizeCmpMinusConst builds up constant expression trees on one side of the
# comparison, in cases like this:
# cmp cmp
# / \\ / \\
#[-]2 -> a[+]
# / \\ / \\
# a 1 2 1
[NormalizeCmpMinusConst, Normalize]
(Eq | Ge | Gt | Le | Lt
(Minus
$leftLeft:^(ConstValue)
$leftRight:(ConstValue)
)
$right:(ConstValue) & (CanConstructBinary Plus $right $leftRight)
)=>
((OpName)
$leftLeft
(Plus $right $leftRight)
)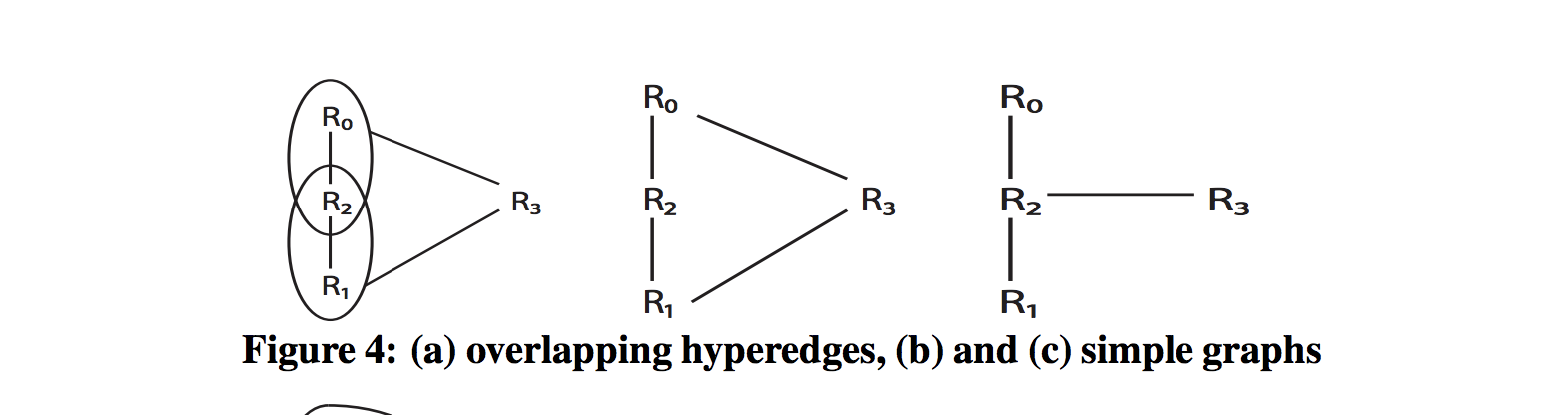
在动态规划算法中,通常用『generate and test』的方式枚举所有计划,而test阶段的效率可能成为瓶颈。更为高效的方式是,用图进行建模,基于连通性来枚举可能的Join方式。
在《Dynamic Programming Strikes Back》和《Counter Strike: Generic Top-Down Join Enumeration for Hypergraphs》中分别提出了通过Hypergraph的方式对Join问题进行建模,不仅在性能上获得很大提升,并且能够处理各种复杂的JOIN。
通常整个查询优化过程都是串行的,但对于一些复杂查询的场景来说,优化过程耗时可能十分明显,因此有必要将优化过程并行化。
对于TopDown来说相对简单,原本的搜索过程就依赖包含了Task之间的依赖关系,因此将原本的Stack换成一个Graph即可实现刻画任务之间的依赖关系,无关的任务可以并行执行。

对于DP来说,由于每一层的搜索会依赖之前的结果,层与层之间不可并行。在每层搜索过程中,可以对搜索空间进行分区,不同分区用不同的线程执行。不过此外会面临一个负载均衡的问题,虽然看起来搜索空间的切分很均衡,但实际在进行Relation 去重之后,可能会出现负载不均。因此关键在于如何划分搜索空间。
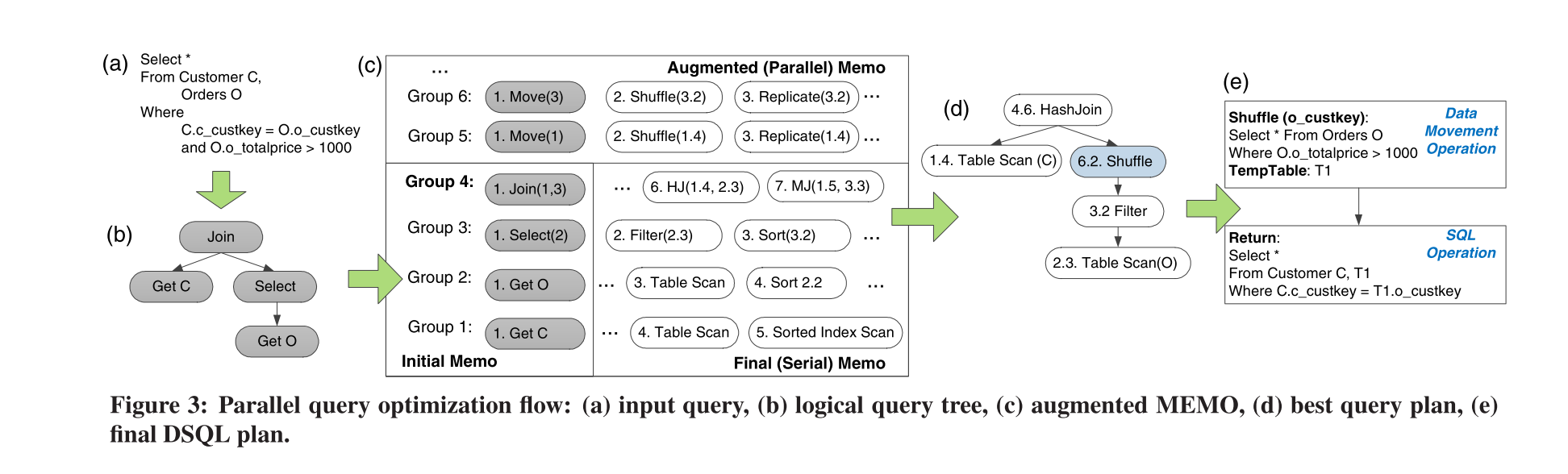
在MPP数据库中,由于需要考虑数据分布,不能简单地将串行的执行计划并行化。执行计划的搜索空间需要考虑数据重分布,并且其代价模型中也需要考虑网络的代价。在SQLServer PDW中,将数据分布加入了Property Enforcer;而MemSQL则采用了自底向上的优化方式,同样也会在搜索空间中考虑数据分布。
本文对Cascades Optimizer所处理的问题背景、基本原理进行了介绍,也对另一种流派-BottomUp进行了比较。虽然在理论层面有不少差别,但由于优化器不仅是个算法问题,还是一个工程问题,最终的扩展性、优化效果、性能还是很大程度上取决于工程实现。工程实现的问题在这里不再赘述,更多的细节可参考Cockroach、Peleton、Orca等项目。
Cascades自称为Framework,意味它仅仅是一个Framework,Framework内部还存在很大的Design Space,具体到优化规则、统计信息、代价模型,每个问题都是一个领域,每个领域都值得更多的探索。本文所述,仅是沧海一粟,不敢以偏概全。





